

17 feb. 2020 | Door: Pascal Vleugels
Beter zoeken en vinden: Sterk verbeterde zoekresultaten in de interne zoekmachine
Onlangs hebben we een aantal wijzigingen doorgevoerd in de manier waarop de zoekmachine op de website werkt. Met deze ingrepen kan de content op de website beter gevonden worden. Door een aanpassing in het zoekalgoritme en de sortering, geeft de interne zoekmachine op de website meer en betere zoekresultaten terug. Je bezoeker vindt dus sneller waar hij naar op zoek is!
De doorgevoerde wijzigingen hebben betrekking op alle locaties, evenementen, arrangementen en routes die vanuit het Open Data Platform komen. In een eerder blogartikel schreven we al over de wijze waarop we de interne zoekmachine wilden verbeteren en sinds kort is deze verbetering voor iedereen beschikbaar.
Er is een grote verbetering zichtbaar in de zoekresultaten, door de sortering op relevantie
We willen graag iets meer info geven over hoe de nieuwe sortering van de zoekfunctie werkt. De nieuwe sorteeroptie “relevantie” werkt op basis van scores die items krijgen op basis van een zoekopdracht. In de praktijk kan het nog steeds voorkomen dat een zoekopdracht onverwachte resultaten oplevert. Om iets meer inzicht te geven hoe de score-berekening nu werkt, hebben we een aantal termen en use-cases op papier gezet. Voor individuele use-cases kunnen we dieper in de resultaten duiken, om te kijken hoe we de zoekfunctie nog verder kunnen optimaliseren.
Woordenlijst
- Zoekmachine
De software welke gebruikt wordt voor het zoekbaar maken van ODP (Open Data Platform) items (Elasticsearch). Met "zoekmachine" bedoelen we dus niet de zoek-websites zoals Google of Bing. - Item
Items uit het ODP (Open Data Platform) zoals een locatie, route of evenement. - Zoekindex
De geïndexeerde items in de zoekmachine Elasticsearch. Er wordt een soort bibliotheek aangelegd van alle items die gevonden moeten kunnen worden. - Indexering
Het opslaan van items in de zoekmachine zodat deze items zoekbaar zijn. Dit wordt opgeslagen in de zoekindex. - Term
Een opgeslagen woord in de zoekmachine
Zo werkt onze zoekmachine
De werking van de zoekfunctionaliteit en de bijbehorende sortering valt samen te vatten in drie stappen:
- Indexeren
- Vinden
- Scoreberekening & sortering
Stap 1: Indexering

Foto door Anthony Martino
Om duidelijk te maken hoe sortering werkt, is het eerst nodig dat het item vindbaar is in de zoekmachine. Kort samengevat worden woorden uit items opgeslagen als termen in de zoekindex (een aantal voorbeelden van woorden die op een ODP detailpagina zouden kunnen staan):
- Hotelkamer: hot, hote, hotel, hotelk, hotelka, hotelkam, hotelkame, hotelkamer
- Hotel: hot, hote, hotel
- Breda: bre, bred, breda
(Dit is nodig zodat de zoekterm “hotel” ook items vindt welke het woord “hotelkamer” bevatten.)
Voor elk item worden de volgende velden geïndexeerd:
- Naam
- Slug (url)
- Korte omschrijving
- Lange omschrijving
- Tags
- Categorieën
- Plaats (boost)
- Straat
(Deze informatie staat allemaal op de ODP detailpagina van een item, of is als metadata beschikbaar)
Nadat de termen opgeslagen zijn in de zoekindex, zijn de items vindbaar. Zodra een item in ODP wordt opgeslagen (of via een import/connector in het ODP wordt geplaatst), wordt direct de zoekindex bijgewerkt.
Stap 2: Vinden

Foto door Jamie Street
Zodra een gebruiker gaat zoeken op de website, worden de zoektermen opgezocht in de zoekindex en wordt het bijbehorende item teruggegeven. Hierbij maakt het niet uit of een item alle zoektermen bevat.
Er dient minimaal één zoekterm overeen te komen met de woorden die zijn geïndexeerd.
Daarnaast is het nog toegestaan dat de gebruiker een typefout maakt. Het is dus mogelijk dat er een item wordt gevonden d.m.v. een typefout welke mogelijk niet gewenst was.
Let op: Omdat we bij deze stap in het zoekproces de items nog niet gaan sorteren, wordt er geen onderscheid gemaakt tussen een gevonden item met een spelfout en een item zonder spelfout.
Stap 3: Score

Foto door Mika Baumeister
Als de bezoeker een zoekopdracht heeft uitgevoerd, geeft Elasticsearch alle items terug die overeenkomen met een of meerdere zoektermen. Deze lijst met resultaten is nog niet op een logische volgorde geordend.
De gevonden resultaten dienen vervolgens nog wel gesorteerd te worden op relevantie, zodat ook het "meest relevante resultaat" bovenaan staat. Dit gebeurt door middel van scores. Elk gevonden resultaat krijgt vanuit de zoekmachine een score. Items met de hoogste scores komen eerst (en staan dus bovenaan in de zoekresultaten).
Score berekening op basis van drie factoren.
De berekeningen die worden uitgevoerd door Elasticsearch om de score te berekenen zijn erg complex. Vaak is wel te herleiden waarom een item een bepaalde score heeft, maar dit is erg arbeidsintensief en is dus onmogelijk om voor elk item uit te voeren. Hieronder lichten we toe welke punten worden meegenomen bij de berekening en welke invloed ze hebben op de score.
Om de scores aan items toe te kennen wordt er gekeken naar de termen binnen de gevonden items. Een aantal items zullen een term meerdere keren bevatten. Daarnaast zijn sommige termen belangrijker dan andere termen.
Deze factoren hebben invloed op de sortering:
- Term frequentie
Hoevaak komt een bepaalde term voor binnen een item? Wanneer de term vaker voorkomt, dan is het item belangrijker. - Omgekeerde item frequentie
Hoevaak komt een term voor binnen alle items? Termen welke over veel items voorkomen zijn minder belangrijk omdat ze minder specifiek zijn. - Lengte van de tekst
Hoe kort is de tekst waarin de term is gevonden? Hoe korter de tekst, hoe specifieker deze overeenkomt met de zoekterm. Korter is beter.
Per geïndexeerd veld worden de punten van de drie bovenstaande factoren bij elkaar opgeteld. Daarnaast is het mogelijk om per veld, een vermenigvuldiger (boost) te gebruiken om de score te vergroten. Momenteel krijgt alleen het veld ‘plaats’ een boost van 3. Zo stimuleren we dat als er gezocht wordt op een “activiteit + plaatsnaam” de plaatsnaam belangrijker wordt voor de ranking.
Voorbeeld van zoekresultaten
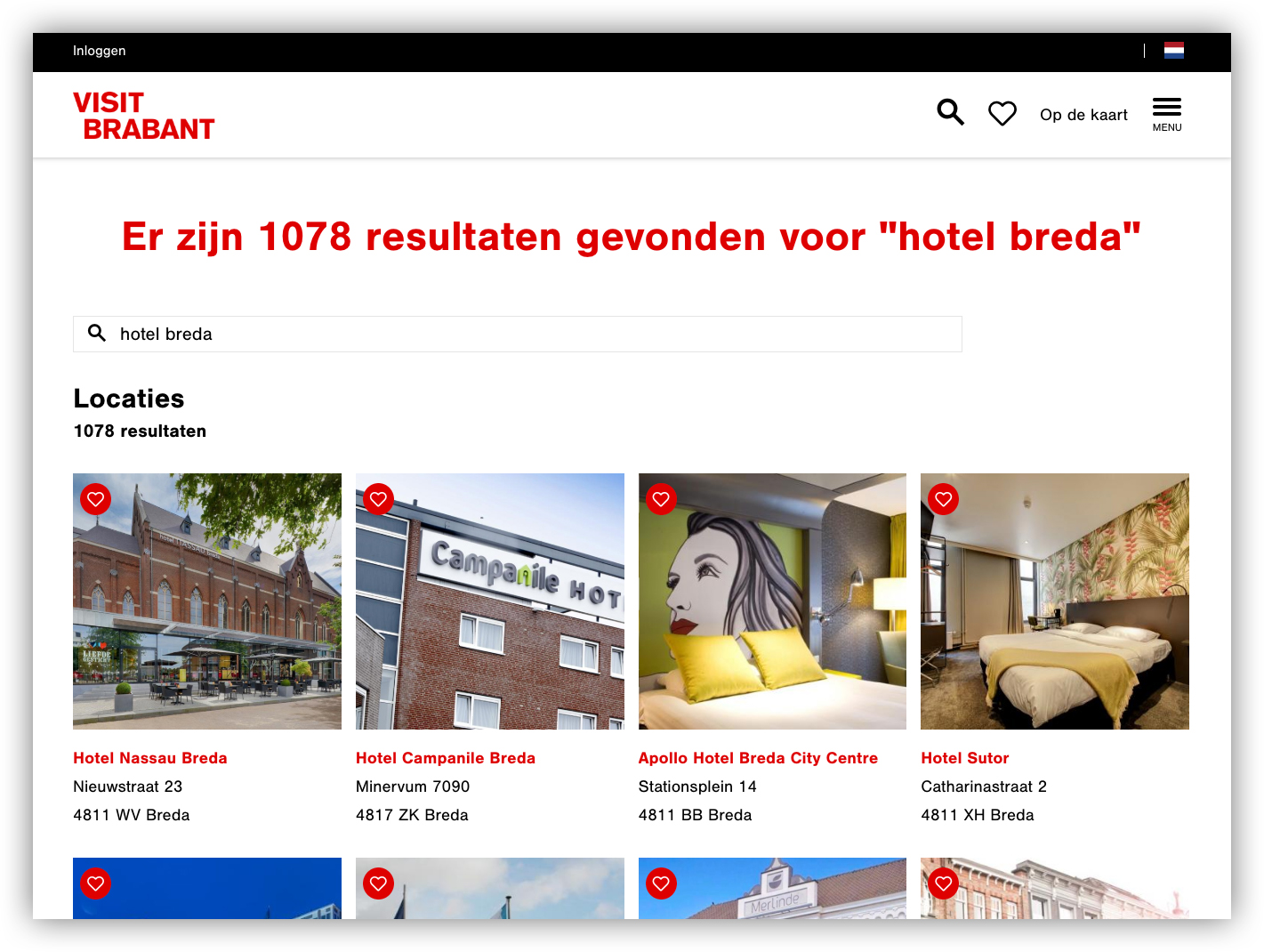
Nu het wat duidelijker is hoe termen invloed hebben op de sortering, geven we een kort voorbeeld van gevallen waarin het toch "onverwachte" resultaten op zou kunnen leveren:
- Zoekopdracht: “hotel breda”
- Zoekresultaat: (2 resultaten)
(voor het gemak gaan we er even vanuit dat we alleen kijken naar de tekstuele omschrijving van de items en niet naar alle andere geïndexeerde velden, zoals bijv: categorie of adres)
-
Resultaat nummer. 1:
“Hotel Rumors beschikt over 17 comfortabele hotelkamers, een restaurant, bar, 2 conferentieruimtes en een overdekt en verwarmd terras.”Resultaat nummer 2:
“In het restaurant ‘de Barones’ van Van der Valk Hotel Princevile Breda zijn de gasten maar ook gasten zonder kamer elke dag van het jaar van harte welkom voor ontbijt, lunch en diner.”
Hotel Rumors komt voor het Van der Valk Hotel. In eerste opzicht lijkt dit verwarrend. Immers, Hotel Rumors komt alleen overeen met de term ‘hotel’ en het Van de Valk hotel komt overeen met de termen ‘hotel’ & ‘breda’.
Echter is het in dit scenario niet helemaal wat er gebeurt. Als je de indexatieregels erop na slaat, gebeurt hier het volgende: bij Hotel Rumors worden er 2 dingen geïndexeerd: ‘hotel’ en ‘hotelk’ (hotelkamer).
‘Hotelk’ komt overeen met hotel wanneer er rekening wordt gehouden met één enkele typefout. Nu hebben beide items dus twee termen welke overeenkomen:
- Hotel Rumors: hotel & hotelk
- Van der Valk: hotel & breda
De term frequentie is voor beide items gelijk. Namelijk (1+1) voor elke term een enkel punt.
De lengte van de tekst heeft weinig invloed. Maar ook hier gaan de meeste punten naar Hotel Rumors aangezien een kortere tekst heeft (echter is dit verwaarloosbaar).
Echter de omgekeerde item frequentie heeft in dit geval wel veel invloed. Wanneer we de termen ‘breda’ en ‘hotelk’ vergelijken dan is het makkelijk aan te nemen dat ‘hotelk’ minder vaak voorkomt over alle items. Deze term wordt dus belangrijker gescoord door ElasticSearch. In dit geval zorgt de uniekheid van de term er dus voor dat Hotel Rumors hoger scoort.
(De oplettende lezer herinnert zich wellicht dat we een boost op de plaatsnaam hebben gezet, dus in de "echte" wereld zou het Van der Valk Hotel wel degelijk hoger in de zoekresultaten staan.)
Sortering op relevantie
De zoekmachine indexeert nu meer, dus geeft ook meer resultaten terug dan voorheen. Doordat de scores nu nog beter bepaald worden en op een nieuwe manier worden gesorteerd, geeft de zoekmachine nu meer relevante zoekresultaten terug.
Vanaf heden wordt de nieuwe score-berekening toegepast bij zoekopdrachten in de interne zoekmachine op de website. Indien er een zoekopdracht (met een zoekterm) wordt uitgevoerd (in de algemene zoekmachine, in de UITagenda of in de ODP overzichten) worden alle resultaten automatisch gesorteerd op relevantie. Voor de UITagenda betekent dat, dat de resultaten vanaf dat moment niet meer automatisch gesorteerd worden op datum (eerstkomende evenement wordt als eerste getoond).
Heb je vragen over de nieuwe werking of kom je een bijzonder zoekresultaat tegen? Laat het ons weten, dan maken we de zoekfunctie samen nóg beter!

Bekijk profiel